안녕하세요.
이번 포스팅에서는, SQL의 꽃이라 불리는 서브쿼리를 준비했습니다.
실무 데이터 분석을 하신다면 꼼꼼히 봐주세요
서브쿼리
하나의 sql문에 포함되어있는 또다른 sql문
주요 서브쿼리 위치 : from절
서브쿼리는 언제 사용할까요?
하나의 sql문으로 풀 수 없는 조금 더 복잡한 데이터를 추출할 때! depth1, depth2 이런식이죠
예시로 함께 이해해보겠습니다
1. 2개 이상의 상품을 구매한 고객은, 주로 어떤 상품을 구매했을까요?
위 문제는 한번에 구하기 어렵습니다
지금까지 배운것으로 진행해보자면
1) 2개 이상의 상품을 구매한 고객
아래와 같이 구할 수 있습니다
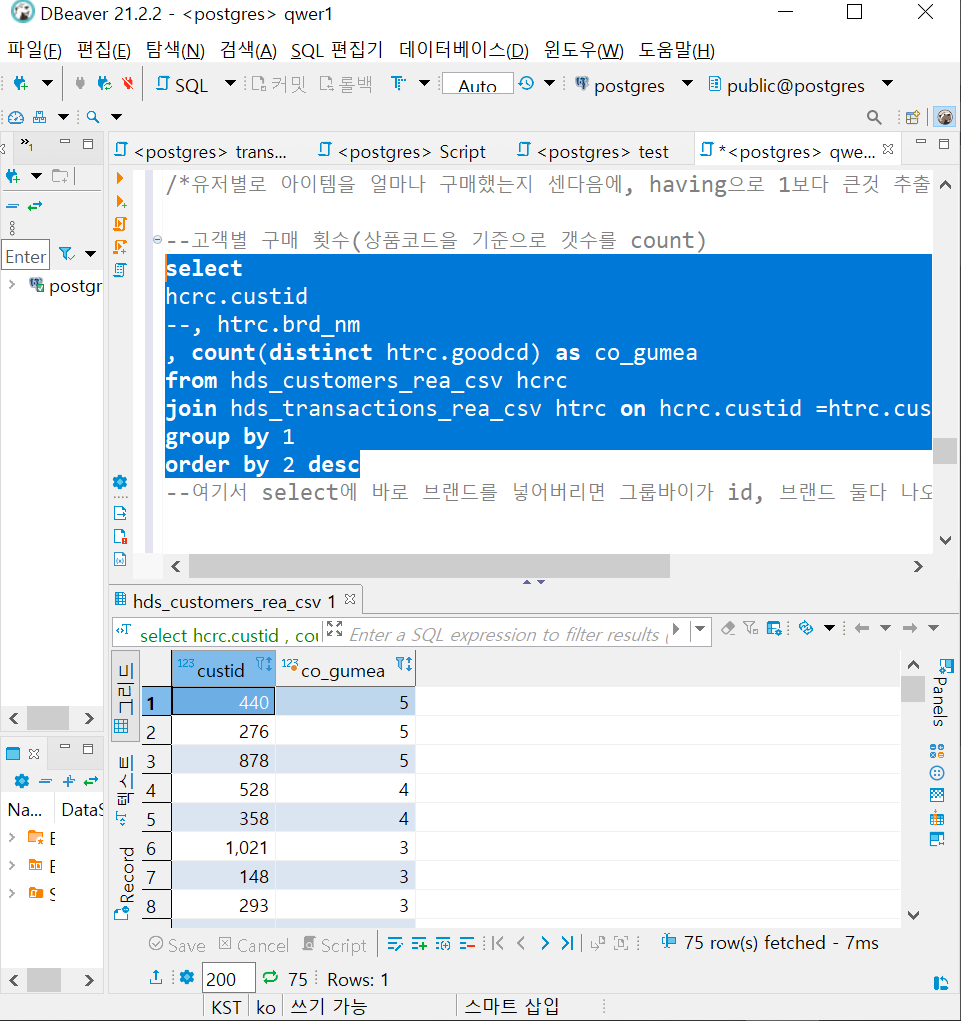
여기에 having절을 추가해서 2개 이상의 상품을 구매한 고객을 추출합니다
select
hcrc.custid
, count(distinct htrc.goodcd) as co_gumea
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid =htrc.custid
group by 1
having count(distinct htrc.goodcd) > 1
order by 2* 순서! having 다음에 order by가 나와야합니다.
* 2개 이상 상품을 구매한 고객을 도출했습니다
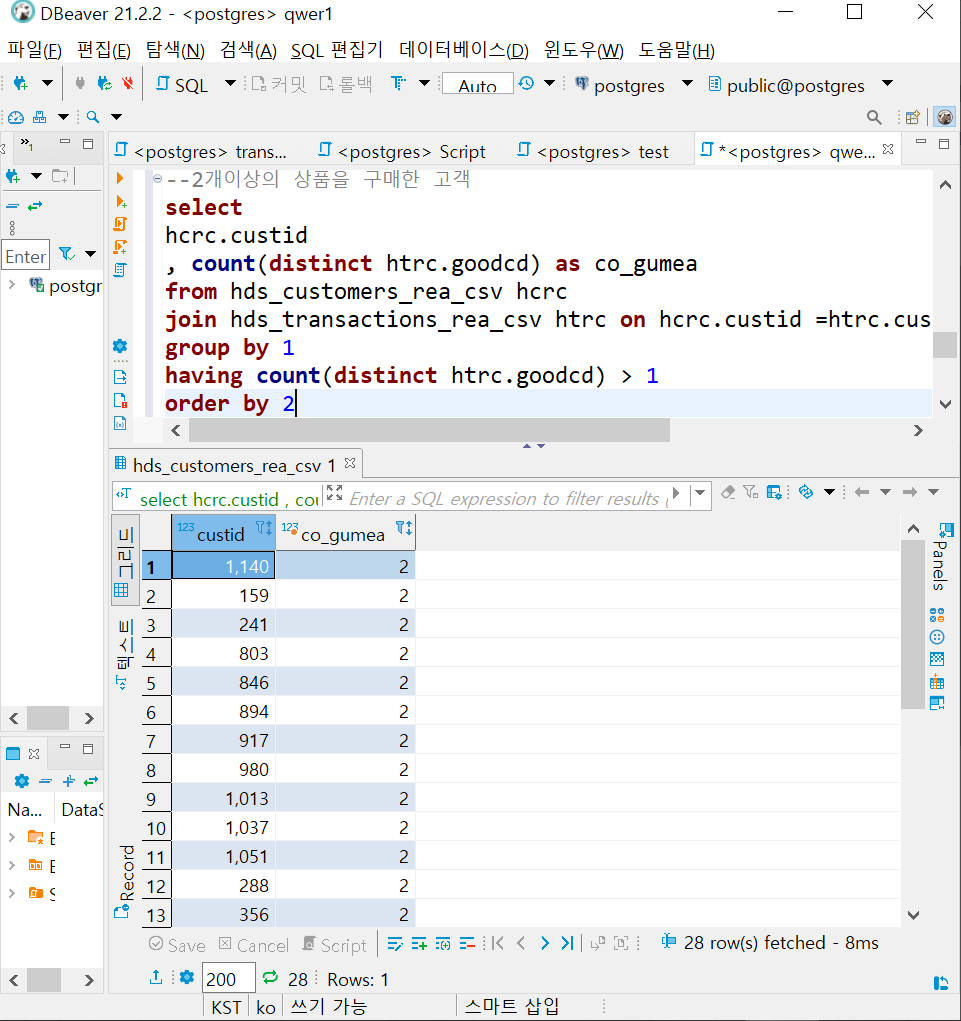
여기서 select에 바로 브랜드를 넣어버리면 그룹바이가 id, 브랜드 둘다 나오게됩니다.
저희가 원하는 결과가 아니죠
그래서, 서브쿼리를 활용해야 합니다!
2) 2개 이상의 상품을 구매한 고객은, 주로 어떤 상품을 구매했을까요?
- 1)의 결과를 하나의 테이블로 생각해서 테이블을 조인합니다
select brd_nm
--, idlist.custid as more2id
, count(brd_nm)
from hds_transactions_rea_csv htrc
join
(select
hcrc.custid
, count(distinct htrc.brd_nm)
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid =htrc.custid
group by 1
having count(distinct htrc.brd_nm) > 1
) idlist on htrc.custid =idlist.custid
group by 1
order by 2 desc기존 1) 테이블과 조인합니다
이너조인이므로 1에 존재하는 id들만 연결->구매 2이상인 고객들만 도출되겠죠
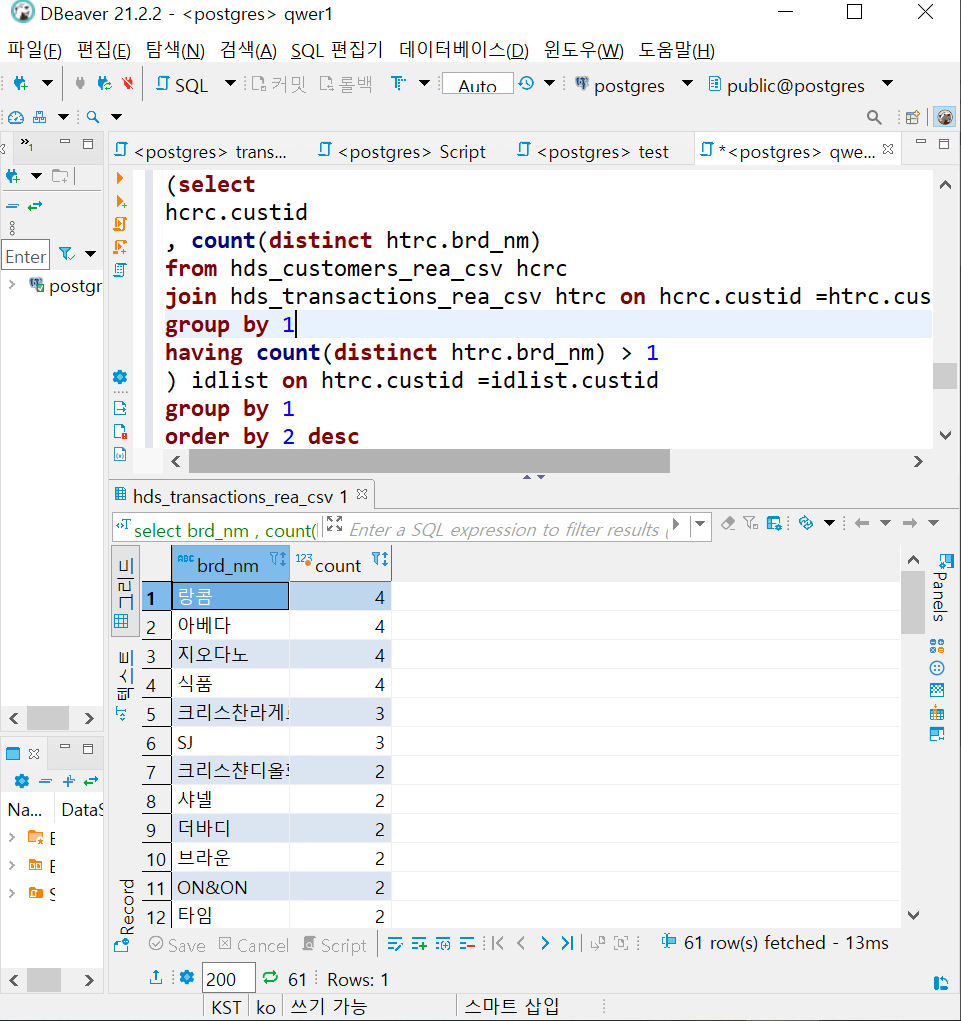
2개 이상의 상품을 구매한 고객들은 주로 랑콤이나 아베다 등의 브랜드를 많이 이용했네요
2. 특정 상품을 구매한 고객은, 해당 상품 외에 추가로 어떤 상품을 구매했을까?
분석에 앞서, 분석이 용이하도록 가장 많이 구매한 품목을 확인해보겠습니다
화장품 품목이 가장 많은 구매가 일어났네요

화장품으로 정하고,
화장품을 구매한 고객 리스트를 확인해볼게요
select
distinct htrc.custid
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid=htrc.custid
where htrc.buyer_nm ='화장품'
본격적으로, 화장품을 구매한 고객들은 추가로 어떤 상품군을 구매했을까요?
먼저 구한 테이블은 조인에 위치시켜 서브쿼리로 계산해보겠습니다
select htrc2.buyer_nm
, count(distinct htrc2 .custid) as 고객
from hds_transactions_rea_csv htrc2
--화장품을 구매한 고객리스트
join
(
select
distinct hcrc.custid
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid=htrc.custid
where htrc.buyer_nm ='화장품'
) cos_list
on htrc2 .custid =cos_list.custid
group by 1이렇게 조인절에 넣어주면, 화장품만 구매한 고객들만 추출이 되겠죠
기존 화장품 구매고객 17명을 제외하고 문화, 스포츠, 캐주얼 등이네요

3. 2개 이상의 상품을 구매한 고객의 연령 분포는?
1) 2개 이상의 상품을 구매한 고객 리스트는 아까 1번에서 구했습니다
select
hcrc.custid
, count(distinct htrc.goodcd) as co_gumea
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid =htrc.custid
group by 1
having count(distinct htrc.goodcd) > 1
order by 2
2) 연령 분포는?
- 기존 문자 birth 컬럼을 ages로 변환해줍니다. ages만 사용하면 되죠. 이전포스팅에 나와있죠
https://s-s-o-story.tistory.com/37
[분석실습] SQL 데이터 사칙연산 심화 (날짜변환, 연산, 고유값)
안녕하세요. 이번 포스팅에서는, SQL의 사칙연산 심화 구문들을 준비했습니다. 실무 데이터 분석을 하신다면 꼼꼼히 봐주세요 사칙연산 심화 거래데이터, 고객데이터를 이용해서 인당 평균 구매
s-s-o-story.tistory.com
select
sex
,birth
, substring(birth, 1,4)
--연도 추출
, cast(substring(birth, 1,4) as integer) as yyyy
--연산을 위해 연도 문자열->숫자 변환
, date_part('year', now()) as now_ye
--현재 연도 추출
, date_part('year', now()) - cast(substring(birth, 1,4) as integer) as ages
-- 현재연도 - 출생연도 = 연령으로 변환
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc .custid =htrc.custid
where birth not like '%nul%' ;여기서 추출한 ages 컬럼을 사용합니다

3). 2개 이상의 상품을 구매한 고객의 연령 분포는?
select
date_part('year', now()) - cast(substring(hcrc .birth , 1,4) as integer) as ages
, count(distinct hcrc.custid) cnt_all_ages
--여기까지 전체 연령 분포
, count(distinct case when cos_list.custid is not null then cos_list.custid else null end) as cos_user_cnt
--화장품유저리스트가 null이 아니면, cos_list안에 있으면 custid고 아니면 null로 처리
--이렇게하면 cos_list안에 있는 id만 추출이 되겠죠
, round(count(distinct case when cos_list.custid is not null then cos_list.custid else null end) ::numeric / count(distinct hcrc.custid) *100, 1) as perc
--화장품 구매고객 수를 전체로 나눠서 퍼센트를 구합니다
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc .custid =htrc.custid
left join
(
select
hcrc.custid
, count(distinct htrc.brd_nm)
from hds_customers_rea_csv hcrc
join hds_transactions_rea_csv htrc on hcrc.custid =htrc.custid
group by 1
having count(distinct htrc.brd_nm) > 1
) cos_list on hcrc .custid =cos_list.custid
where birth not like '%nul%'
group by 1
;조금 복잡해보이지만 쉽습니다
* 먼저 서브쿼리 절에서 left join을 해준 이유는
기존 연령 분포와, 화장품을 산 고객의 연령 분포를 비교해주고 싶기때문입니다
from customer t1
left join cos_list t2
on t1.id = t2.id
형식이니, customer 테이블은 전체가 출력되죠
* 참고로 여기서는
from customer t1
join transaction t2
left join cos_list t3
on t1.id = t3.id
형식이니,
t1, t2의 교집합 이너조인이 먼저입니다
해당 이너조인이 left역할을 하게됩니다
*다시 확인하자면,
select *
from a
left join b
on a.id = b.id
형식에서 a는 모두 출력이되고 b는 a에서 해당하는 것만 출력하게 됩니다
* 그 다음 select절을 보면 아래 구문이 있는데
count(distinct case when cos_list.custid is not null then cos_list.custid else null end) as cos_user_cnt
서브쿼리 테이블 cos_list id가 널이 아니면, cos_list안에 있으면 custid로 반영, 아니면 null로 처리합니다
-> 이렇게하면 cos_list안에 있는 id만 추출이 됩니다
* 바로 아래 round절은 위 count절을 전체 custid로 나눠서 화장품 구매고객/전체 퍼센트를 구합니다

전체 연령 분포는 첫번째 컬럼입니다. 2번째 컬럼은 count한 것인데, 42세 43세가 가장 많네요
그 중 화장품을 구매한 고객은 마찬가지로 42세 43세가 가장 많습니다
더미 데이터라 결과가 명확하지는 않지만 이렇게 서브쿼리를 이용해서 2depth의 분석도 할 수 있습니다
'IT_SQL' 카테고리의 다른 글
| [분석 기초] SQL 데이터 유형 총정리(문자형, 숫자형, 날짜형, 참/거짓, 변환) (0) | 2021.11.17 |
|---|---|
| [분석실습] SQL 데이터 사칙연산 심화 (날짜변환, 연산, 고유값) (0) | 2021.11.16 |
| Question) join 후 sum 오류 (0) | 2021.11.14 |
| [분석실습] SQL 데이터 사칙연산 (round, 소수점, 반올림, 퍼센트~) (0) | 2021.11.14 |
| [분석실습] SQL 데이터 날짜함수 가공하기(now, date_part, current, interval ~) (0) | 2021.11.12 |